HMM-BASED SPEECH SYNTHESIS SYSTEM
Introduction
We have proposed an HMM-based speech synthesis system.
In the system,
pitch and state duration are modeled by multi-space
probability distribution HMMs and multi-dimensional
Gaussian distributions, respectively.
The distributions for spectral parameter, pitch
parameter and the state duration are clustered
independently by using a decision-tree based context
clustering technique.
Modeling of spectrum, pitch and duration
In the system, spectrum, pitch and duration are
modeled by HMM.
We use mel-cepstral coefficients
as spectral parameter.
Sequences of mel-cepstral coefficient vector,
which are obtained from speech database
using a mel-cepstral analysis technique
are modeled by continuous density HMMs.
The mel-cepstral analysis technique enables speech to be
re-synthesized from the mel-cepstral coefficients using
the MLSA (Mel Log Spectrum Approximation) filter
.
Pitch patterns are modeled by a hidden Markov model based on
multi-space probability distribution (MSD-HMM)
We cannot apply the conventional discrete or
continuous HMMs to pitch pattern modeling since the
observation sequence of pitch pattern is composed of
one-dimensional continuous values and a discrete symbol which
represents ``unvoiced''.
The MSD-HMM includes discrete HMM and
continuous mixture HMM as special cases, and further can model
the sequence of observation vectors with variable dimension
including zero-dimensional observations, i.e., discrete
symbols. As a result, MSD-HMMs can model pitch patterns
without heuristic assumption.
We construct spectrum and excitation models
by using embedded training
because the embedded training does not need
label boundaries when appropriate initial models are available.
However, if spectrum models and excitation models
are embedded-trained separately,
speech segmentations may be discrepant between them.
To avoid this problem,
context dependent HMMs are trained with feature vector
which consists of spectrum, excitation and their dynamic features.
State duration densities are
modeled by single Gaussian distributions.
Dimension of state duration densities is
equal to the number of state of HMM,
and the nth dimension of state duration densities
is corresponding to the nth state of HMMs.
When we construct context dependent models
taking account of many combinations of the above contextual factors,
we expect to be able to obtain appropriate models.
However,
as contextual factors increase,
their combinations also increase exponentially.
Therefore,
model parameters with sufficient accuracy cannot be
estimated with limited training data.
Furthermore,
it is impossible to prepare speech database
which includes all combinations of contextual factors.
To overcome this problem,
we apply a decision-tree based context
clustering technique
to distributions for spectrum, excitation and state duration.
The decision-tree based context clustering algorithm
have been extended for MSD-HMMs.
Since each of spectrum, excitation and duration have its own
influential contextual factors,
the distributions for spectral parameter and excitation
parameter and the state duration are clustered
independently.
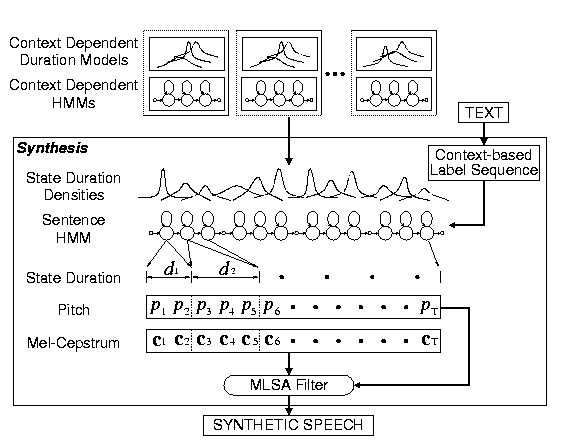
Text-to-Speech Synthesis
In the synthesis part,
an arbitrarily given text to be synthesized is
converted to a context-based label sequence.
Then, according to the label sequence,
a sentence HMM is constructed by concatenating
context dependent HMMs.
State durations of the sentence HMM are determined
so as to maximize the likelihood of the state
duration densities
According to the obtained state durations,
a sequence of mel-cepstral coefficients and excitation parameter
is generated from the sentence HMM
by using the speech parameter generation algorithm.
Finally,
speech is synthesized directly
from the generated mel-cepstral coefficients and excitation parameter
by the MLSA filter.
Examples
HMMs were trained using
phonetically balanced 450 sentences from ATR Japanese
speech database for training.
Speech signals were sampled at 16~kHz and windowed
by a 25-ms Blackman window with a 5-ms shift,
and then mel-cepstral coefficients were obtained by
the mel-cepstral analysis.
Feature vector consists of
spectral and excitation parameter vectors.
Spectral parameter vector consists of 25 mel-cepstral
coefficients including the zeroth coefficient,
their delta and delta-delta coefficients.
Excitaiton parameter vector consists of log pitch,
bandpass voicing strength, Fourier magnitude and
their delta and delta-delta.
We used 5-state left-to-right HMMs with
single diagonal Gaussian output distributions.
Examples of speech generated from our TTS system