#include <sent/stddefs.h>
#include <sent/ptree.h>
#include <sent/vocabulary.h>
ngram2.hのインクルード依存関係図
このグラフは、どのファイルから直接、間接的にインクルードされているかを示しています。
データ構造 | |
| struct | NGRAM_INFO |
| Main N-gram structure [詳細] | |
マクロ定義 | |
| #define | MAX_N 3 |
| Maximum number of N (now fixed to trigram) | |
| #define | NNID_INVALID -1 |
| Value to indicate no id | |
| #define | NNID_INVALID_UPPER 255 |
| Value to indicate no id at NNID_UPPER | |
| #define | NNIDMAX 16711680 |
| Allowed maximum number of NNID (255*65536) | |
| #define | BINGRAM_IDSTR "julius_bingram_v3" |
| Header string to identify version of bingram (v3: <= rev.3.4.2) | |
| #define | BINGRAM_IDSTR_V4 "julius_bingram_v4" |
| Header string to identify version of bingram (v4: >= rev.3.5) | |
| #define | BINGRAM_HDSIZE 512 |
| Bingram header size in bytes | |
| #define | BINGRAM_SIZESTR_HEAD "word=" |
| Bingram header info string to identify the unit byte (head) | |
| #define | BINGRAM_SIZESTR_BODY_4BYTE "4byte(int)" |
| Bingram header string that indicates 4 bytes unit | |
| #define | BINGRAM_SIZESTR_BODY_2BYTE "2byte(unsigned short)" |
| Bingram header string that indicates 2 bytes unit | |
| #define | BINGRAM_SIZESTR_BODY BINGRAM_SIZESTR_BODY_2BYTE |
| #define | BINGRAM_BYTEORDER_HEAD "byteorder=" |
| Bingram header info string to identify the byte order (head) (v4) | |
| #define | BINGRAM_NATURAL_BYTEORDER "LE" |
| Bingram header info string to identify the byte order (body) (v4) | |
型定義 | |
| typedef unsigned char | NNID_UPPER |
| Type definition for N-gram word ID | |
| typedef unsigned short | NNID_LOWER |
| Type definition for N-gram word ID | |
| typedef int | NNID |
| Type definition for N-gram word ID | |
関数 | |
| NNID | search_bigram (NGRAM_INFO *ndata, WORD_ID w_l, WORD_ID w_r) |
| LOGPROB | uni_prob (NGRAM_INFO *ndata, WORD_ID w) |
| LOGPROB | bi_prob_lr (NGRAM_INFO *ndata, WORD_ID w1, WORD_ID w2) |
| LOGPROB | bi_prob_rl (NGRAM_INFO *ndata, WORD_ID w1, WORD_ID w2) |
| LOGPROB | tri_prob_rl (NGRAM_INFO *ndata, WORD_ID w1, WORD_ID w2, WORD_ID w3) |
| boolean | ngram_read_arpa (FILE *fp, NGRAM_INFO *ndata, int direction) |
| void | set_unknown_id (NGRAM_INFO *ndata) |
| Set unknown word ID to the N-gram data. | |
| boolean | ngram_read_bin (FILE *fp, NGRAM_INFO *ndata) |
| boolean | ngram_write_bin (FILE *fp, NGRAM_INFO *ndata, char *header_str) |
| void | ngram_make_lookup_tree (NGRAM_INFO *ndata) |
| WORD_ID | ngram_lookup_word (NGRAM_INFO *ndata, char *wordstr) |
| WORD_ID | make_ngram_ref (NGRAM_INFO *, char *) |
| NGRAM_INFO * | ngram_info_new () |
| void | ngram_info_free (NGRAM_INFO *ngram) |
| void | init_ngram_bin (NGRAM_INFO *ndata, char *ngram_file) |
| void | init_ngram_arpa (NGRAM_INFO *ndata, char *lrfile, char *rlfile) |
| void | ngram_compact_bigram_context (NGRAM_INFO *ndata) |
| void | print_ngram_info (NGRAM_INFO *ndata) |
| void | make_voca_ref (NGRAM_INFO *ndata, WORD_INFO *winfo) |
Julius では,前向き2-gramと後向き3-gram を用います.入力ファイル形式は ARPA形式とJulius独自のバイナリ形式の2つをサポートしています. 前者の場合,前向き2-gram と後向き3-gram をそれぞれ別々のファイルとして 指定します.後者の場合,それらが統合された1つのバイナリファイルを 読み込みます.読み込みは後者のほうが高速です.なお,Julius 内部では, どちらも同じ構造体 NGRAM_INFO に格納されます.
上記の前提のほとんどは,これらの2つのN-gramを同一のコーパスから 学習することで満たされます.最後の条件については,3-gram のカットオフ 値に 2-gram のカットオフ値と同値かそれ以上の値を指定すればOKです. 与えられたN-gramが上記を満たさない場合,Julius はエラーを出します.
ngram2.h で定義されています。
| NNID search_bigram | ( | NGRAM_INFO * | ndata, | |
| WORD_ID | w_l, | |||
| WORD_ID | w_r | |||
| ) |
Search for 2-gram tuple (w_l, w_r) in the 2-gram part of N-gram.
| ndata | [in] word/class N-gram | |
| w_l | [in] left word/class ID in N-gram | |
| w_r | [in] right word/class ID in N-gram |
ngram_access.c の 39 行で定義されています。
参照元 add_bigram_rl()・bi_prob_lr()・bi_prob_rl()・tri_prob_rl().
| LOGPROB uni_prob | ( | NGRAM_INFO * | ndata, | |
| WORD_ID | w | |||
| ) |
Get 1-gram probability of 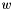 in log10.
in log10.
| ndata | [in] word/class N-gram | |
| w | [in] word/class ID in N-gram |
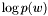 .
. ngram_access.c の 154 行で定義されています。
| LOGPROB bi_prob_lr | ( | NGRAM_INFO * | ndata, | |
| WORD_ID | w1, | |||
| WORD_ID | w2 | |||
| ) |
Get LR 2-gram probability of word/class sequence 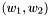 in log10
in log10
| ndata | [in] word/class N-gram | |
| w1 | [in] left word/class ID in N-gram | |
| w2 | [in] right word/class ID in N-gram (to compute probability) |
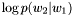 .
. ngram_access.c の 175 行で定義されています。
| LOGPROB bi_prob_rl | ( | NGRAM_INFO * | ndata, | |
| WORD_ID | w1, | |||
| WORD_ID | w2 | |||
| ) |
Get RL 2-gram probability of word/class sequence in log10.
| ndata | [in] word/class N-gram | |
| w1 | [in] left word/class ID in N-gram (to compute probability) | |
| w2 | [in] right word/class ID in N-gram |
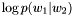 .
. ngram_access.c の 206 行で定義されています。
参照元 tri_prob_rl().
| LOGPROB tri_prob_rl | ( | NGRAM_INFO * | ndata, | |
| WORD_ID | w1, | |||
| WORD_ID | w2, | |||
| WORD_ID | w3 | |||
| ) |
Get RL 3-gram probability of word/class sequence 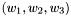 in log10.
in log10.
| ndata | [in] word/class N-gram | |
| w1 | [in] left word/class ID in N-gram (to compute probability) | |
| w2 | [in] middle word/class ID in N-gram | |
| w3 | [in] right word/class ID in N-gram |
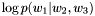 .
. ngram_access.c の 239 行で定義されています。
| boolean ngram_read_arpa | ( | FILE * | fp, | |
| NGRAM_INFO * | ndata, | |||
| int | direction | |||
| ) |
Read in one ARPA N-gram file, either LR 2-gram or RL 3-gram.
| fp | [in] file pointer | |
| ndata | [out] N-gram data to store the read data | |
| direction | [in] specify whether this is LR 2-gram or RL 3-gram |
ngram_read_arpa.c の 518 行で定義されています。
参照元 init_ngram_arpa().
| void set_unknown_id | ( | NGRAM_INFO * | ndata | ) |
Set unknown word ID to the N-gram data.
In CMU-Cam SLM toolkit, OOV words are always mapped to UNK, which always appear at the very beginning of N-gram entry, so we fix the unknown word ID at "0".
| ndata | [out] N-gram data to set unknown word ID. |
ngram_read_arpa.c の 72 行で定義されています。
参照元 ngram_read_arpa().
| boolean ngram_read_bin | ( | FILE * | fp, | |
| NGRAM_INFO * | ndata | |||
| ) |
Read a N-gram binary file and store to data.
| fp | [in] file pointer | |
| ndata | [out] N-gram data to store the read data |
ngram_read_bin.c の 230 行で定義されています。
参照元 init_ngram_bin().
| boolean ngram_write_bin | ( | FILE * | fp, | |
| NGRAM_INFO * | ndata, | |||
| char * | headerstr | |||
| ) |
Write a whole N-gram data in binary format.
| fp | [in] file pointer | |
| ndata | [in] N-gram data to write | |
| headerstr | [in] user header string |
ngram_write_bin.c の 128 行で定義されています。
| void ngram_make_lookup_tree | ( | NGRAM_INFO * | ndata | ) |
Make index tree for searching N-gram ID from the entry name.
| ndata | [in] N-gram data |
ngram_lookup.c の 34 行で定義されています。
| WORD_ID ngram_lookup_word | ( | NGRAM_INFO * | ndata, | |
| char * | wordstr | |||
| ) |
Look up N-gram ID by entry name.
| ndata | [in] N-gram data | |
| wordstr | [in] entry name to search |
ngram_lookup.c の 64 行で定義されています。
| WORD_ID make_ngram_ref | ( | NGRAM_INFO * | ndata, | |
| char * | wstr | |||
| ) |
Return N-gram ID of entry name, or unknown class ID if not found.
| ndata | [in] N-gram data | |
| wstr | [in] entry name to search |
ngram_lookup.c の 84 行で定義されています。
参照元 make_voca_ref().
| NGRAM_INFO* ngram_info_new | ( | ) |
Allocate a new N-gram structure.
ngram_malloc.c の 33 行で定義されています。
| void ngram_info_free | ( | NGRAM_INFO * | ndata | ) |
| void init_ngram_bin | ( | NGRAM_INFO * | ndata, | |
| char * | bin_ngram_file | |||
| ) |
Read and setup N-gram data from binary format file.
| ndata | [out] pointer to N-gram data structure to store the data | |
| bin_ngram_file | [in] file name of the binary N-gram |
init_ngram.c の 35 行で定義されています。
| void init_ngram_arpa | ( | NGRAM_INFO * | ndata, | |
| char * | ngram_lr_file, | |||
| char * | ngram_rl_file | |||
| ) |
Read and setup N-gram data from ARPA format files of 2-gram and 3-gram.
| ndata | [out] pointer to N-gram data structure to store the data | |
| ngram_lr_file | [in] file name of ARPA 2-gram file | |
| ngram_rl_file | [in] file name of ARPA reverse 3-gram file |
init_ngram.c の 60 行で定義されています。
| void ngram_compact_bigram_context | ( | NGRAM_INFO * | ndata | ) |
Compact the 2-gram context information.
| ndata | [i/o] N-gram data |
ngram_read_arpa.c の 630 行で定義されています。
参照元 ngram_read_arpa().
| void print_ngram_info | ( | NGRAM_INFO * | ndata | ) |
Output misccelaneous information of N-gram to standard output.
| ndata | [in] N-gram data |
ngram_util.c の 97 行で定義されています。
参照元 print_info().
| void make_voca_ref | ( | NGRAM_INFO * | ndata, | |
| WORD_INFO * | winfo | |||
| ) |
Make correspondence between word dictionary and N-gram vocabulary.
| ndata | [i/o] word/class N-gram, the unknown word information will be set. | |
| winfo | [i/o] word dictionary, the word-to-ngram-entry mapping will be done here. |
init_ngram.c の 100 行で定義されています。
 1.5.0
1.5.0