
|
Grammar / Dictionary APIのコラボレーション図
|
|
関数 | |
| void | multigram_add_gramlist (char *dfafile, char *dictfile, JCONF_LM *j, int lmvar) |
| 起動時読み込みリストに文法を追加する. | |
| void | multigram_remove_gramlist (JCONF_LM *j) |
| 起動時読み込みリストを消す. | |
| boolean | multigram_add_prefix_list (char *prefix_list, char *cwd, JCONF_LM *j, int lmvar) |
| プレフィックスから複数の文法を起動時読み込みリストに追加する. | |
| boolean | multigram_add_prefix_filelist (char *listfile, JCONF_LM *j, int lmvar) |
| リストファイルを読み込み複数文法を起動時読み込みリストに追加する. | |
| void | schedule_grammar_update (Recog *recog) |
| 全文法の変更をチェックし,必要であれば認識用辞書を再構築するよう エンジンに要求する. | |
| void | j_reset_reload (Recog *recog) |
| 再構築要求フラグをクリアする. | |
| boolean | multigram_build (RecogProcess *r) |
| グローバル文法を調べ,必要があれば木構造化辞書を(再)構築する. | |
| int | multigram_add (DFA_INFO *dfa, WORD_INFO *winfo, char *name, PROCESS_LM *lm) |
| 新たな文法を,文法リストに追加する. | |
| boolean | multigram_delete (int delid, PROCESS_LM *lm) |
| 文法を削除する. | |
| void | multigram_delete_all (PROCESS_LM *lm) |
| すべての文法を次回更新時に削除するようマークする. | |
| int | multigram_activate (int gid, PROCESS_LM *lm) |
| 文法を有効化する. | |
| int | multigram_deactivate (int gid, PROCESS_LM *lm) |
| 文法を無効化する. | |
| boolean | multigram_update (PROCESS_LM *lm) |
| グローバル文法の更新 | |
| int | multigram_get_all_num (PROCESS_LM *lm) |
| 現在ある文法の数を得る(active/inactiveとも). | |
| int | multigram_get_gram_from_category (int category, PROCESS_LM *lm) |
| 単語カテゴリの属する文法を得る. | |
| int | multigram_get_gram_from_wid (WORD_ID wid, PROCESS_LM *lm) |
| 単語IDから属する文法を得る. | |
| int | multigram_get_id_by_name (PROCESS_LM *lm, char *gramname) |
| LM中の文法を名前で検索し,その文法IDを返す. | |
| MULTIGRAM * | multigram_get_grammar_by_name (PROCESS_LM *lm, char *gramname) |
| LM中の文法を名前で検索する. | |
| MULTIGRAM * | multigram_get_grammar_by_id (PROCESS_LM *lm, unsigned short id) |
| LM中の文法を ID 番号で検索する. | |
| boolean | multigram_add_words_to_grammar (PROCESS_LM *lm, MULTIGRAM *m, WORD_INFO *winfo) |
| 単語集合を文法に追加する. | |
| boolean | multigram_add_words_to_grammar_by_name (PROCESS_LM *lm, char *gramname, WORD_INFO *winfo) |
| 名前で指定された文法に単語集合を追加する. | |
| boolean | multigram_add_words_to_grammar_by_id (PROCESS_LM *lm, unsigned short id, WORD_INFO *winfo) |
| 番号で指定された文法に単語集合を追加する. | |
| void multigram_add_gramlist | ( | char * | dfafile, | |
| char * | dictfile, | |||
| JCONF_LM * | j, | |||
| int | lmvar | |||
| ) |
起動時読み込みリストに文法を追加する.
| dfafile | [in] DFAファイル | |
| dictfile | [in] 単語辞書 | |
| j | [in] LM 設定パラメータ | |
| lmvar | [in] LM 詳細型 id |
gramlist.c の 66 行で定義されています。
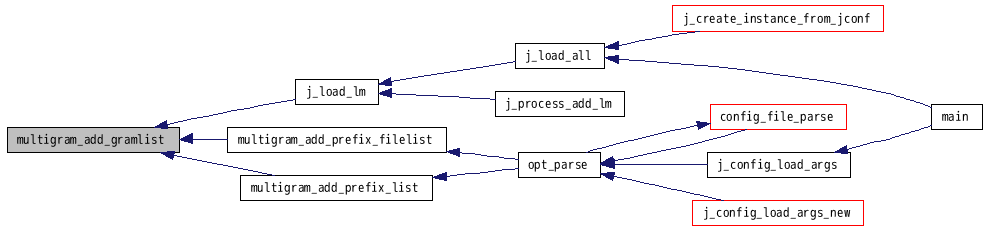
参照元 j_load_lm()・multigram_add_prefix_filelist()・multigram_add_prefix_list().
呼出しグラフ:
| void multigram_remove_gramlist | ( | JCONF_LM * | j | ) |
起動時読み込みリストを消す.
| j | [in] LM 設定パラメータ |
gramlist.c の 103 行で定義されています。
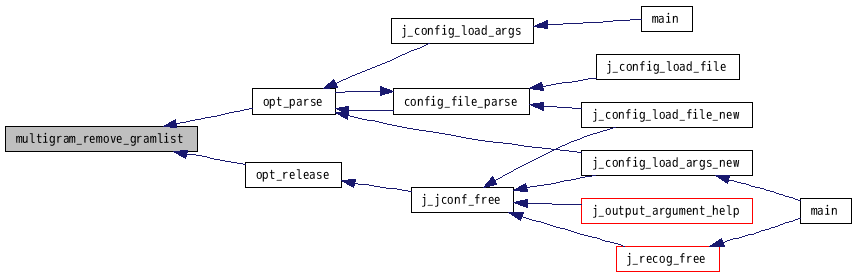
参照元 opt_parse()・opt_release().
呼出しグラフ:
プレフィックスから複数の文法を起動時読み込みリストに追加する.
プレフィックスは "foo", あるいは "foo,bar" のようにコンマ区切りで 複数与えることができます. 各文字列の後ろに ".dfa", ".dict" をつけた ファイルを,それぞれ文法ファイル・辞書ファイルとして順次読み込みます. 読み込まれた文法は順次,文法リストに追加されます.
| prefix_list | [in] プレフィックスのリスト | |
| cwd | [in] カレントディレクトリの文字列 | |
| j | [in] LM 設定パラメータ | |
| lmvar | [in] LM 詳細型 id |
gramlist.c の 163 行で定義されています。
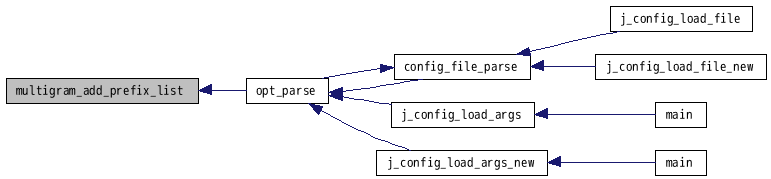
参照元 opt_parse().
呼出しグラフ:
リストファイルを読み込み複数文法を起動時読み込みリストに追加する.
ファイル内に1行に1つずつ記述された文法のプレフィックスから, 対応する文法ファイルを順次読み込みます.
各行の文字列の後ろに ".dfa", ".dict" をつけたファイルを, それぞれ文法ファイル・辞書ファイルとして順次読み込みます. 読み込まれた文法は順次,文法リストに追加されます.
| listfile | [in] プレフィックスリストのファイル名 | |
| j | [in] LM 設定パラメータ | |
| lmvar | [in] LM 詳細型 id |
gramlist.c の 265 行で定義されています。
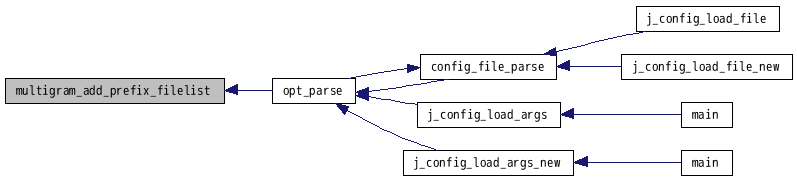
参照元 opt_parse().
呼出しグラフ:
| void schedule_grammar_update | ( | Recog * | recog | ) |
| void j_reset_reload | ( | Recog * | recog | ) |
| boolean multigram_build | ( | RecogProcess * | r | ) |
グローバル文法を調べ,必要があれば木構造化辞書を(再)構築する.
グローバル辞書に変更があれば,その更新されたグローバル 辞書から木構造化辞書などの音声認識用データ構造を再構築する.
| r | [in] recognition process instance |
multi-gram.c の 173 行で定義されています。
参照元 j_launch_recognition_instance()・j_recognize_stream_core().
呼出しグラフ:

| int multigram_add | ( | DFA_INFO * | dfa, | |
| WORD_INFO * | winfo, | |||
| char * | name, | |||
| PROCESS_LM * | lm | |||
| ) |
新たな文法を,文法リストに追加する.
現在インスタンスが保持している文法のリストは lm->grammars に保存される. 追加した文法には,newbie, active のフラグがセットされ,次回の 文法更新チェック時に更新対象となる.
| dfa | [in] 追加登録する文法のDFA情報 | |
| winfo | [in] 追加登録する文法の辞書情報 | |
| name | [in] 追加登録する文法の名称 | |
| lm | [i/o] 言語処理インスタンス |
multi-gram.c の 277 行で定義されています。
参照元 multigram_read_file_and_add().
呼出しグラフ:

| boolean multigram_delete | ( | int | delid, | |
| PROCESS_LM * | lm | |||
| ) |
文法を削除する.
文法リスト中のある文法について,削除マークを付ける. 実際の削除は multigram_exec_delete() で行われる.
| delid | [in] 削除する文法の文法ID | |
| lm | [i/o] 言語処理インスタンス |
multi-gram.c の 332 行で定義されています。
| void multigram_delete_all | ( | PROCESS_LM * | lm | ) |
| int multigram_activate | ( | int | gid, | |
| PROCESS_LM * | lm | |||
| ) |
文法を有効化する.
ここでは次回更新時に 反映されるようにマークをつけるのみである.
| gid | [in] 有効化したい文法の ID | |
| lm | [i/o] 言語処理インスタンス |
multi-gram.c の 445 行で定義されています。
| int multigram_deactivate | ( | int | gid, | |
| PROCESS_LM * | lm | |||
| ) |
文法を無効化する.
無効化された文法は 認識において仮説展開されない. これによって,グローバル辞書を 再構築することなく,一時的に個々の文法をON/OFFできる. 無効化した 文法は multigram_activate() で再び有効化できる. なおここでは 次回の文法更新タイミングで反映されるようにマークをつけるのみである.
| gid | [in] 無効化したい文法のID | |
| lm | [i/o] 言語処理インスタンス |
multi-gram.c の 507 行で定義されています。
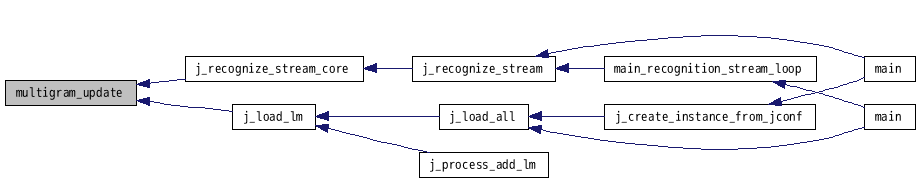
| boolean multigram_update | ( | PROCESS_LM * | lm | ) |
グローバル文法の更新
前回呼出しからの文法リストの変更をチェックする. リスト中に削除マークがつけられた文法がある場合は,その文法を削除し, グローバル辞書を再構築する. 新たに追加された文法がある場合は, その文法を現在のグローバル辞書の末尾に追加する.
| lm | [i/o] 言語処理インスタンス |
multi-gram.c の 619 行で定義されています。
参照元 j_load_lm()・j_recognize_stream_core().
呼出しグラフ:
| int multigram_get_all_num | ( | PROCESS_LM * | lm | ) |
現在ある文法の数を得る(active/inactiveとも).
| lm | [i/o] 言語処理インスタンス |
multi-gram.c の 926 行で定義されています。
参照元 j_recognize_stream_core()・outfile_sentence()・output_result()・store_result_pass2().
呼出しグラフ:

| int multigram_get_gram_from_category | ( | int | category, | |
| PROCESS_LM * | lm | |||
| ) |
単語カテゴリの属する文法を得る.
| category | 単語カテゴリID | |
| lm | [i/o] 言語処理インスタンス |
multi-gram.c の 958 行で定義されています。
参照元 store_result_pass2().
呼出しグラフ:
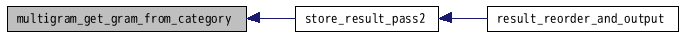
| int multigram_get_gram_from_wid | ( | WORD_ID | wid, | |
| PROCESS_LM * | lm | |||
| ) |
| int multigram_get_id_by_name | ( | PROCESS_LM * | lm, | |
| char * | gramname | |||
| ) |
LM中の文法を名前で検索し,その文法IDを返す.
| lm | [in] LM process instance | |
| gramname | [in] grammar name |
multi-gram.c の 1060 行で定義されています。
| MULTIGRAM* multigram_get_grammar_by_name | ( | PROCESS_LM * | lm, | |
| char * | gramname | |||
| ) |
LM中の文法を名前で検索する.
| lm | [in] LM process instance | |
| gramname | [in] grammar name |
multi-gram.c の 1093 行で定義されています。
参照元 multigram_add_words_to_grammar_by_name().
呼出しグラフ:

| MULTIGRAM* multigram_get_grammar_by_id | ( | PROCESS_LM * | lm, | |
| unsigned short | id | |||
| ) |
LM中の文法を ID 番号で検索する.
| lm | [in] LM process instance | |
| id | [in] ID number |
multi-gram.c の 1126 行で定義されています。
参照元 multigram_add_words_to_grammar_by_id().
呼出しグラフ:

| boolean multigram_add_words_to_grammar | ( | PROCESS_LM * | lm, | |
| MULTIGRAM * | m, | |||
| WORD_INFO * | winfo | |||
| ) |
単語集合を文法に追加する.
追加する単語の文法カテゴリIDについては,すでにアサインされているものが そのままコピーされる.よって,それらはこの関数を呼び出す前に, 追加対象の文法で整合性が取れるよう正しく設定されている必要がある. 木構造化辞書全体が,後に再構築される.
単語N-gram言語モデルへの辞書追加は現在サポートされていない.
| lm | [i/o] LM process instance | |
| m | [i/o] grammar to which the winfo will be appended | |
| winfo | [in] words to be added to the grammar |
multi-gram.c の 1175 行で定義されています。
参照元 multigram_add_words_to_grammar_by_id()・multigram_add_words_to_grammar_by_name().
呼出しグラフ:

| boolean multigram_add_words_to_grammar_by_name | ( | PROCESS_LM * | lm, | |
| char * | gramname, | |||
| WORD_INFO * | winfo | |||
| ) |
名前で指定された文法に単語集合を追加する.
multigram_add_words_to_grammar() を文法名で指定して実行する.
| lm | [i/o] LM process instance | |
| gramname | [in] name of the grammar to which the winfo will be appended | |
| winfo | [in] words to be added to the grammar |
multi-gram.c の 1228 行で定義されています。
| boolean multigram_add_words_to_grammar_by_id | ( | PROCESS_LM * | lm, | |
| unsigned short | id, | |||
| WORD_INFO * | winfo | |||
| ) |
番号で指定された文法に単語集合を追加する.
multigram_add_words_to_grammar() を番号で指定して実行する.
| lm | [i/o] LM process instance | |
| id | [in] ID number of the grammar to which the winfo will be appended | |
| winfo | [in] words to be added to the grammar |
multi-gram.c の 1259 行で定義されています。
 1.5.1
1.5.1
