Data Structures
Defines
Typedefs
Functions
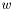 in log10.
in log10.
#include <sent/stddefs.h>
#include <sent/ptree.h>
#include <sent/vocabulary.h>
Go to the source code of this file.
Data Structures | |
| struct | NGRAM_TUPLE_INFO |
| N-gram entries for a m-gram (1 <= m <= N). More... | |
| struct | __ngram_info__ |
| Main N-gram structure. More... | |
Defines | |
| #define | MAX_N 10 |
| Maximum number of N for N-gram. | |
| #define | NNID_INVALID 0xffffffff |
| Value to indicate no id (full). | |
| #define | NNID_MAX 0xfffffffe |
| Value of maximum value (full). | |
| #define | NNID_INVALID_UPPER 255 |
| Value to indicate no id at NNID_UPPER (24bit). | |
| #define | NNID_MAX_24 16711679 |
| Allowed maximum number of id (255*65536-1) (24bit). | |
| #define | BEGIN_WORD_DEFAULT "<s>" |
| Default word string of beginning-of-sentence word. | |
| #define | END_WORD_DEFAULT "</s>" |
| Default word string of end-of-sentence word. | |
| #define | UNK_WORD_DEFAULT "<unk>" |
| Default word string of unknown word for open vocabulary. | |
| #define | UNK_WORD_DEFAULT2 "<UNK>" |
| #define | UNK_WORD_MAXLEN 30 |
| Maximum length of unknown word string. | |
| #define | BINGRAM_IDSTR "julius_bingram_v3" |
| Header string to identify version of bingram (v3: <= rev.3.4.2). | |
| #define | BINGRAM_IDSTR_V4 "julius_bingram_v4" |
| Header string to identify version of bingram (v4: <= rev.3.5.3). | |
| #define | BINGRAM_IDSTR_V5 "julius_bingram_v5" |
| Header string to identify version of bingram (v5: >= rev.4.0). | |
| #define | BINGRAM_HDSIZE 512 |
| Bingram header size in bytes. | |
| #define | BINGRAM_SIZESTR_HEAD "word=" |
| Bingram header info string to identify the unit byte (head). | |
| #define | BINGRAM_SIZESTR_BODY_4BYTE "4byte(int)" |
| Bingram header string that indicates 4 bytes unit. | |
| #define | BINGRAM_SIZESTR_BODY_2BYTE "2byte(unsigned short)" |
| Bingram header string that indicates 2 bytes unit. | |
| #define | BINGRAM_SIZESTR_BODY BINGRAM_SIZESTR_BODY_2BYTE |
| #define | BINGRAM_BYTEORDER_HEAD "byteorder=" |
| Bingram header info string to identify the byte order (head) (v4). | |
| #define | BINGRAM_NATURAL_BYTEORDER "LE" |
| Bingram header info string to identify the byte order (body) (v4). | |
Typedefs | |
| typedef unsigned int | NNID |
| Type definition for N-gram entry ID (full). | |
| typedef unsigned char | NNID_UPPER |
| N-gram entry ID (24bit: upper bit). | |
| typedef unsigned short | NNID_LOWER |
| N-gram entry ID (24bit: lower bit). | |
| typedef __ngram_info__ | NGRAM_INFO |
| Main N-gram structure. | |
Functions | |
| NNID | search_ngram (NGRAM_INFO *ndata, int n, WORD_ID *w) |
| Search for N-tuples. | |
| LOGPROB | ngram_prob (NGRAM_INFO *ndata, int n, WORD_ID *w) |
| Get N-gram probability of the last word w_n, given context w_1^n-1. | |
| LOGPROB | uni_prob (NGRAM_INFO *ndata, WORD_ID w) |
| Get 1-gram probability of in log10. | |
| LOGPROB | bi_prob (NGRAM_INFO *ndata, WORD_ID w1, WORD_ID w2) |
| Get 2-gram probability This function is not used in Julius, since each function of bi_prob_* will be called directly from the search. | |
| void | bi_prob_func_set (NGRAM_INFO *ndata) |
| Determinte which bi-gram computation function to be used according to the N-gram type, and set pointer to the proper function into the N-gram data. | |
| boolean | ngram_read_arpa (FILE *fp, NGRAM_INFO *ndata, boolean addition) |
| Read in one ARPA N-gram file. | |
| boolean | ngram_read_bin (FILE *fp, NGRAM_INFO *ndata) |
| Read a N-gram binary file and store to data. | |
| boolean | ngram_write_bin (FILE *fp, NGRAM_INFO *ndata, char *header_str) |
| Write a whole N-gram data in binary format. | |
| boolean | ngram_compact_context (NGRAM_INFO *ndata, int n) |
| Compaction of back-off elements in N-gram data. | |
| void | ngram_make_lookup_tree (NGRAM_INFO *ndata) |
| Make index tree for searching N-gram ID from the entry name. | |
| WORD_ID | ngram_lookup_word (NGRAM_INFO *ndata, char *wordstr) |
| Look up N-gram ID by entry name. | |
| WORD_ID | make_ngram_ref (NGRAM_INFO *, char *) |
| Return N-gram ID of entry name, or unknown class ID if not found. | |
| NGRAM_INFO * | ngram_info_new () |
| Allocate a new N-gram structure. | |
| void | ngram_info_free (NGRAM_INFO *ngram) |
| Free N-gram data. | |
| boolean | init_ngram_bin (NGRAM_INFO *ndata, char *ngram_file) |
| Read and setup N-gram data from binary format file. | |
| boolean | init_ngram_arpa (NGRAM_INFO *ndata, char *ngram_file, int dir) |
| Read and setup N-gram data from ARPA format file. | |
| boolean | init_ngram_arpa_additional (NGRAM_INFO *ndata, char *bigram_file) |
| Read additional LR 2-gram for 1st pass. | |
| void | set_unknown_id (NGRAM_INFO *ndata, char *str) |
| Set unknown word ID to the N-gram data. | |
| void | print_ngram_info (FILE *fp, NGRAM_INFO *ndata) |
| Output misccelaneous information of N-gram to standard output. | |
| boolean | make_voca_ref (NGRAM_INFO *ndata, WORD_INFO *winfo) |
| Make correspondence between word dictionary and N-gram vocabulary. | |
| void | fix_uniprob_srilm (NGRAM_INFO *ndata, WORD_INFO *winfo) |
| Fix unigram probability of BOS / EOS word. | |
This file defines a structure for word N-gram language model. Julius now support N-gram for arbitrary N (maximum number of N is defined as MAX_N, and N should be >= 2).
Both direction of forward (left-to-right) N-gram and backward (right-to-left) N-gram is supported. Since the final recognition process is done by right-to-left direction, using backward N-gram is recommended.
A forward 2-gram is necessary for the 1st recognition pass. If a forward N-gram is specified, Julius simply use its 2-gram part for the 1st pass. If only backward N-gram is specified, Julius calculate the forward probability from the defined backward N-gram by the equation "P(w_2|w_1) = P(w_1|w_2) * P(w_2) / P(w_1)." If both forward N-gram and backward N-gram are specified, Julius uses the 2-gram part of the forward n-gram at the 1st pass, and use the backward N-gram at the 2nd pass as the main LM. Note that the last behavior is the same as previous versions (<=3.5.x)
ARPA standard format and Julius binary format is supported. The binary format can be loaded much faster at startup, so it is recommended to use binary format by converting from ARPA format N-gram beforehand. All combination of N-gram (forward only, backward only, forward 2-gram + backward N-gram) is supported.
The first three requirements can be fullfilled easily if you train the forward bigram and reverse trigram on the same training text. The last condition can be qualified if you set a cut-off value of trigram which is larger or equal to that of bigram. These conditions are checked when Julius or mkbingram reads in the ARPA models, and output error if not cleared.
From 3.5, tuple ID on 2-gram changed from 32bit to 24bit, and 2-gram back-off weights will not be saved if the corresponding 3-gram is empty. They will be performed when reading N-gram to reduce memory size.
Definition in file ngram2.h.
| typedef struct __ngram_info__ NGRAM_INFO |
Main N-gram structure.
bigrams and trigrams are stored in the form of sequential lists. They are grouped by the same context, and referred from the context ((N-1)-gram) data by the beginning ID and its number.
| NNID search_ngram | ( | NGRAM_INFO * | ndata, | |
| int | n, | |||
| WORD_ID * | w | |||
| ) |
Search for N-tuples.
| ndata | [in] word/class N-gram | |
| n | [in] N of N-gram (= number of words in w) | |
| w | [in] word sequence |
Definition at line 103 of file ngram_access.c.
Referenced by add_bigram().
| LOGPROB ngram_prob | ( | NGRAM_INFO * | ndata, | |
| int | n, | |||
| WORD_ID * | w | |||
| ) |
Get N-gram probability of the last word w_n, given context w_1^n-1.
| ndata | [in] word/class N-gram | |
| n | [in] N of N-gram (= number of words in w) | |
| w | [in] word sequence |
Definition at line 135 of file ngram_access.c.
Referenced by ngram_forw2back(), and ngram_prob().
| LOGPROB uni_prob | ( | NGRAM_INFO * | ndata, | |
| WORD_ID | w | |||
| ) |
Get 1-gram probability of in log10.
| ndata | [in] word/class N-gram | |
| w | [in] word/class ID in N-gram |
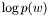 .
. Definition at line 229 of file ngram_access.c.
Referenced by get_nbest_uniprob(), and max_successor_prob().
| LOGPROB bi_prob | ( | NGRAM_INFO * | ndata, | |
| WORD_ID | w1, | |||
| WORD_ID | w2 | |||
| ) |
Get 2-gram probability This function is not used in Julius, since each function of bi_prob_* will be called directly from the search.
| ndata | [in] N-gram data that holds the 2-gram | |
| w1 | [in] left context word | |
| w2 | [in] right target word |
Definition at line 419 of file ngram_access.c.
| void bi_prob_func_set | ( | NGRAM_INFO * | ndata | ) |
Determinte which bi-gram computation function to be used according to the N-gram type, and set pointer to the proper function into the N-gram data.
| ndata | [i/o] N-gram information to use |
Definition at line 449 of file ngram_access.c.
Referenced by ngram_read_bin().
| boolean ngram_read_arpa | ( | FILE * | fp, | |
| NGRAM_INFO * | ndata, | |||
| boolean | addition | |||
| ) |
Read in one ARPA N-gram file.
Supported combinations are LR 2-gram, RL 3-gram and LR 3-gram.
| fp | [in] file pointer | |
| ndata | [out] N-gram data to store the read data | |
| addition | [in] TRUE if going to read additional 2-gram |
Definition at line 525 of file ngram_read_arpa.c.
Referenced by init_ngram_arpa(), and init_ngram_arpa_additional().
| boolean ngram_read_bin | ( | FILE * | fp, | |
| NGRAM_INFO * | ndata | |||
| ) |
Read a N-gram binary file and store to data.
| fp | [in] file pointer | |
| ndata | [out] N-gram data to store the read data |
Definition at line 597 of file ngram_read_bin.c.
Referenced by init_ngram_bin().
| boolean ngram_write_bin | ( | FILE * | fp, | |
| NGRAM_INFO * | ndata, | |||
| char * | headerstr | |||
| ) |
Write a whole N-gram data in binary format.
| fp | [in] file pointer | |
| ndata | [in] N-gram data to write | |
| headerstr | [in] user header string |
Definition at line 135 of file ngram_write_bin.c.
| boolean ngram_compact_context | ( | NGRAM_INFO * | ndata, | |
| int | n | |||
| ) |
Compaction of back-off elements in N-gram data.
| ndata | [i/o] N-gram information | |
| n | [i] N of N-gram |
Definition at line 39 of file ngram_compact_context.c.
| void ngram_make_lookup_tree | ( | NGRAM_INFO * | ndata | ) |
Make index tree for searching N-gram ID from the entry name.
| ndata | [in] N-gram data |
Definition at line 35 of file ngram_lookup.c.
Referenced by ngram_read_bin().
| WORD_ID ngram_lookup_word | ( | NGRAM_INFO * | ndata, | |
| char * | wordstr | |||
| ) |
Look up N-gram ID by entry name.
| ndata | [in] N-gram data | |
| wordstr | [in] entry name to search |
Definition at line 65 of file ngram_lookup.c.
Referenced by add_bigram(), add_unigram(), make_ngram_ref(), and set_unknown_id().
| WORD_ID make_ngram_ref | ( | NGRAM_INFO * | ndata, | |
| char * | wstr | |||
| ) |
Return N-gram ID of entry name, or unknown class ID if not found.
| ndata | [in] N-gram data | |
| wstr | [in] entry name to search |
Definition at line 85 of file ngram_lookup.c.
Referenced by make_voca_ref().
| NGRAM_INFO* ngram_info_new | ( | ) |
Allocate a new N-gram structure.
Definition at line 34 of file ngram_malloc.c.
Referenced by initialize_ngram().
| void ngram_info_free | ( | NGRAM_INFO * | ndata | ) |
Free N-gram data.
| ndata | [in] N-gram data |
Definition at line 68 of file ngram_malloc.c.
Referenced by initialize_ngram(), and j_process_lm_free().
| boolean init_ngram_bin | ( | NGRAM_INFO * | ndata, | |
| char * | bin_ngram_file | |||
| ) |
Read and setup N-gram data from binary format file.
| ndata | [out] pointer to N-gram data structure to store the data | |
| bin_ngram_file | [in] file name of the binary N-gram |
Definition at line 36 of file init_ngram.c.
Referenced by initialize_ngram().
| boolean init_ngram_arpa | ( | NGRAM_INFO * | ndata, | |
| char * | ngram_file, | |||
| int | dir | |||
| ) |
Read and setup N-gram data from ARPA format file.
| ndata | [out] pointer to N-gram data structure to store the data | |
| ngram_file | [in] file name of ARPA (reverse) 3-gram file | |
| dir | [in] direction (DIR_LR | DIR_RL) |
Definition at line 65 of file init_ngram.c.
Referenced by initialize_ngram().
| boolean init_ngram_arpa_additional | ( | NGRAM_INFO * | ndata, | |
| char * | bigram_file | |||
| ) |
Read additional LR 2-gram for 1st pass.
| ndata | [out] pointer to N-gram data structure to store the data | |
| bigram_file | [in] file name of ARPA 2-gram file |
Definition at line 98 of file init_ngram.c.
Referenced by initialize_ngram().
| void set_unknown_id | ( | NGRAM_INFO * | ndata, | |
| char * | str | |||
| ) |
Set unknown word ID to the N-gram data.
| ndata | [out] N-gram data to set unknown word ID. | |
| str | [in] word name string of unknown word |
Definition at line 169 of file init_ngram.c.
Referenced by initialize_ngram().
| void print_ngram_info | ( | FILE * | fp, | |
| NGRAM_INFO * | ndata | |||
| ) |
Output misccelaneous information of N-gram to standard output.
| fp | [in] file pointer | |
| ndata | [in] N-gram data |
Definition at line 79 of file ngram_util.c.
Referenced by print_engine_info().
| boolean make_voca_ref | ( | NGRAM_INFO * | ndata, | |
| WORD_INFO * | winfo | |||
| ) |
Make correspondence between word dictionary and N-gram vocabulary.
| ndata | [i/o] word/class N-gram, the unknown word information will be set. | |
| winfo | [i/o] word dictionary, the word-to-ngram-entry mapping will be done here. |
Definition at line 127 of file init_ngram.c.
Referenced by initialize_ngram().
| void fix_uniprob_srilm | ( | NGRAM_INFO * | ndata, | |
| WORD_INFO * | winfo | |||
| ) |
Fix unigram probability of BOS / EOS word.
This function checks the probabilities of BOS / EOS word, and if it is set to "-99", give the same as another one. This is the case when the LM is trained by SRILM, which assigns unigram probability of "-99" to the beginning-of-sentence word, and causes search on reverse direction to fail.
| ndata | [i/o] N-gram data | |
| winfo | [i/o] Vocabulary information |
Definition at line 206 of file init_ngram.c.
Referenced by initialize_ngram().
 1.5.1
1.5.1